우리는 지금까지 Q 테이블을 이용하여 강화학습을 이해했다.

이제 우리가 학습한 내용을 16*4의 테이블이 아닌 100*100*의 크기의 테이블에도 적용할 수 있으며 화면에 출력하는 방식이 2가지의 색을 사용하고 80*80의 이미지를 사용하면 2^(80*80)이다. 한 이미지당 검은색 흰색을 가진다고 가정했을 때이다. 이 수를 계산했을 때 과연 Q 테이블로 가능할까? 라는 의문을 가지면 당연히 안된다. 엄청나게 큰 수이기 때문이다.

위의 문제는 일반적인 Q 테이블로는 해결하기 힘들기 때문에 우리는 여기서 해결 책을 찾았다.


그것은 바로 인공신경망이다. 입력으로 state s, action a 를 신경망에 넣어주게 된다면 더 적은 계산을 통해 출력을 해주지 않을까? 라는 아이디어다. 여기서 더 간단하게 진행을 하기 위해 우리는 s state만 입력을 해줄 것이다. 그러면 가능한 action에 대한 출력을 해줄 것이다.(오른쪽 사진을 참고하면 된다.)

방금 말한 것과 같이 두가지 방식이 존재한다 입력을 2개하고 1개의 출력을 받거나 1개의 입력을 하고 3개의 action을 받거나


우리가 이걸 학습을 할텐데 입력으로 s 가 들어올때 선형회기를 히든 레이어로 사용한다면 우리는 Ws라는 출력을 받을 것이다. 우리가 딥러닝을 제대로 학습했다면 잘 이해를 할것이다. 이 Ws라는 값은 가설 값으로 이제 라벨 값과 비교를 하여 최소가 되게 하는 것을 진행해야한다.
우리는 여기서 오른쪽 그림을 보게 된다면 y라는 값을 최적의 Q를 구하는 법을 배웠다 optimal Q라고 한다.
y = r(지금 받는 보상) + 감마(discount vector)* maxQ(다음 상태에서 받을 최대의 값) 이다. 여기서 Ws는 Q-predict리고 하자. 이 두개의 값의 차이의 제곱을 최소화하면 된다.



이제 Ws라는 값을 Q의 햍이라 부르겠다. 햍이라는 것은 예측값을 말한다. 이걸 정리하면 s를 입력받고 어떤 a라고는 하지만 그냥 s만 써도 된다. 근데 뒤에 상태를 나타내는 | 세타가 있을 것이다. 이러한 세타는 weight를 말한다. NETWORK 라고도 할수 있다. 뒤의 세타로 인해 결과의 값들이 영향을 받을 것이다.

따라서 우리는 일반적으로 알고 있는 COST 함수의 모양에 따라 (가설-정답)^2 의 방식을 사용해서 최소가 되는 W 값 이예시에서는 쎄타를 구하면된다. 그러면 우리가 이러한 Q-learning을 어떠한 방법으로 학습을 진행하게 될까?

위의 알고리즘을 해석해보면
1. 이 network에 w를 랜덤하게 준다.
2. 초기 상태를 받아온 후 전처리한다. (파이라고 하는데 전처리하고 한다.)
3. 이제 어떤 액션을 할지 선택한다. e-greedy를 사용한다. 아니면 argmax방식을 사용해서 가져온다.
4. 액션을 하게되면 상태와 reward를 돌려준다.
그럼 이제 이걸 가지고 학습을 진행하면 된다.
이 방식을 자세히 보면다면
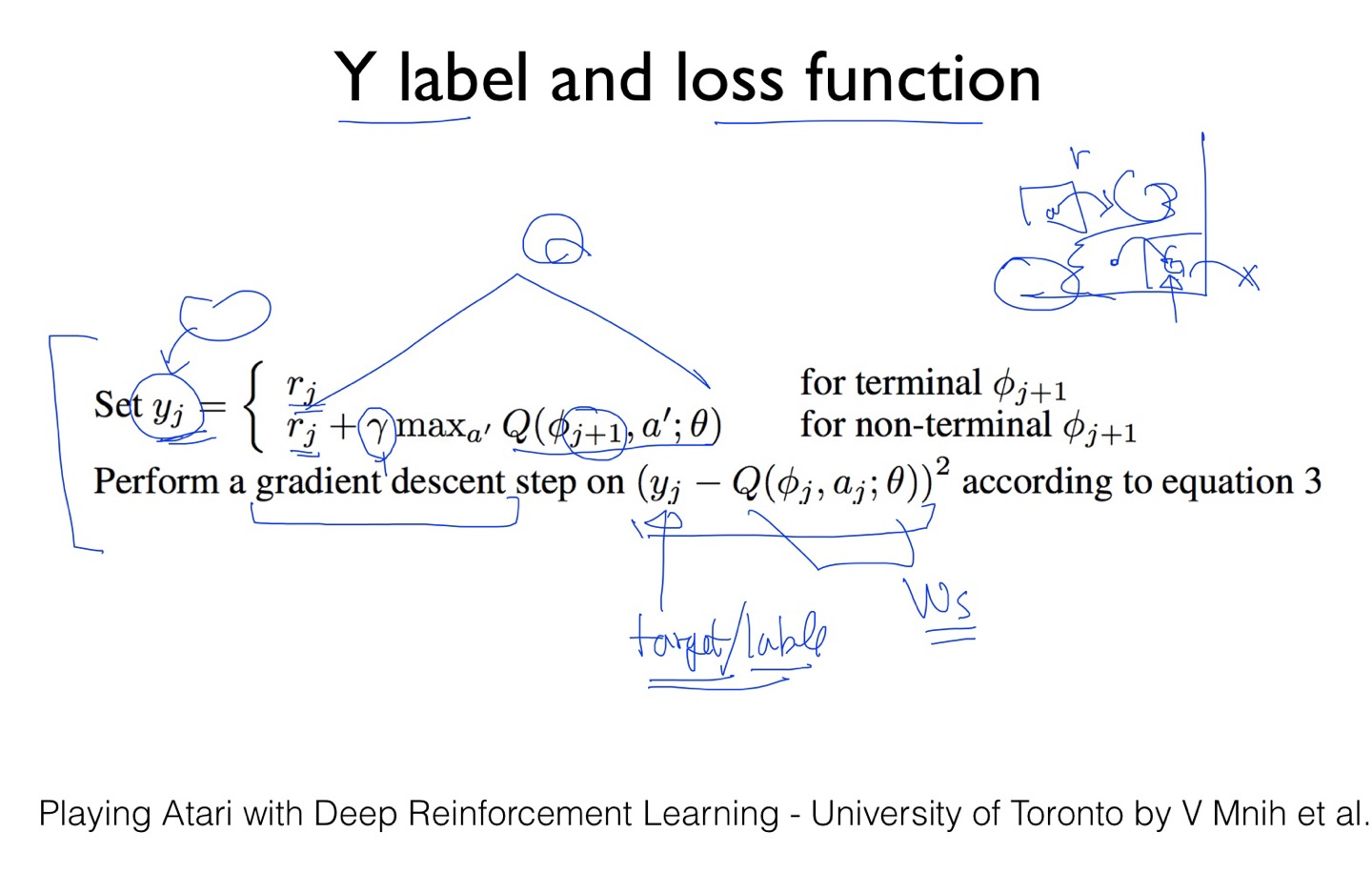
Y 라는 라벨과 손실함수가 있다.
Y 라는 값을 두가지로 표현한다. terminal 상태와 non-terminal 이있다. terminal이라는 단어의 의미에는 종결이라는 의미도 있다. 즉, 마지막에 도착했을때의 상태와 아닌 상태를 의미한다. 마지막에 도착을 했을 때는 r만 돌려주고 아닌 상태에서는 Q value를 받는다.
참고로 위의 알고리즘은 딥마인드에서 만든 알고리즘이다. 이걸 이해한다면 아주 많이 이해한것이란다!

하지만 우리는 위의 방식이 아닌 더 완벽한 Q를 배웠다 근데 왜 사용 안할까? 이러한 이유는 네트워크라는 점에서 조금씩 학습을 하는 것이기 때문에 위의 식과 네트워크의 방식이 같다고 할 수 있다. 따라서 더 복잡한 식을 사용 안해도 된다.


그럼 우리가 지금까지 공부한 것이 뉴럴네트워크에서 Q 테이블의 값이 과연 수렴을 할까? 라는 의문을 가지지만 이 뉴럴넷에서는 안되고 분산하게 된다.
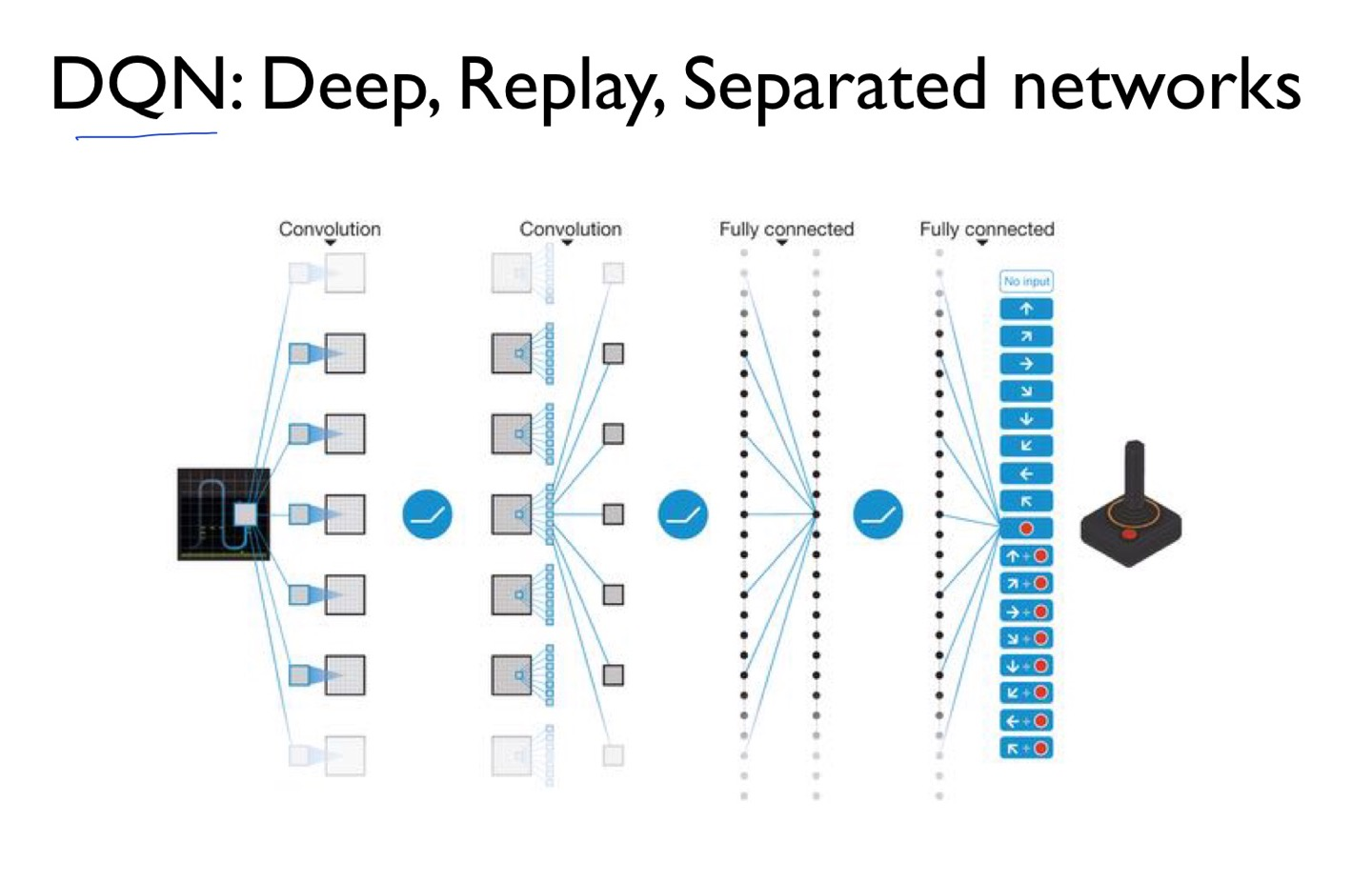
하지만 또 이걸 해결한 팀이 딥마인드이다 ㄷㄷ 역시 구글이다. 암튼 다음 시간에 이걸 공부해보겠다!
'AI > 강화학습' 카테고리의 다른 글
| 7. DQN (0) | 2022.05.17 |
|---|---|
| 2. Playing OpenAI GYM Games (0) | 2022.05.16 |
| 5. Q-learning in non-deterministic world (0) | 2022.05.16 |
| 4. Q-learning exploit&exploration and discounted reward (0) | 2022.05.16 |
| 3. Dummy Q-learning (0) | 2022.05.15 |