문자열의 길이가 일정한 경우 이 문자열들을 저장하고 관리하는데 최적의 자료 구조는 무엇일까요? 연결 리스트, 트리, 또는 해시 테이블이 최선의 방안이 될 수 있을까요? 이번 강의에서는 ‘트라이’라는 자료구조에 대해 알아보겠습니다.
트라이의 원리와 구조를 설명할 수 있습니다.
- 트라이
‘트라이’는 기본적으로 ‘트리’ 형태의 자료 구조입니다.
트라이는 retrieval 의 줄임 말이다.
특이한 점은 각 노드가 ‘배열’로 이루어져있다는 것입니다.
예를 들어 영어 알파벳으로 이루어진 문자열 값을 저장한다고 한다면 이 노드는 a부터 z까지의 값을 가지는 배열이 됩니다.
그리고 배열의 각 요소, 즉 알파벳은 다음 층의 노드(a-z 배열)를 가리킵니다.
아래 그림과 같이 Hermione, Harry, Hagrid 세 문자열을 트라이에 저장해보겠습니다.
루트 노드를 시작으로 각 화살표가 가리키는 알파벳을 따라가면서 노드를 이어주면 됩니다.
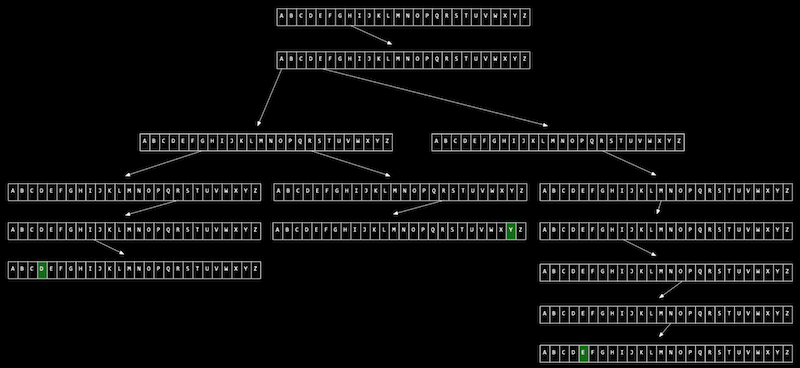
위와 같은 트라이에서 값을 검색하는데 걸리는 시간은 ‘문자열의 길이’에 의해 한정됩니다.
단순히 문자열의 각 문자를 보며 트리를 탐색해나가기만 하면 되니까요.
일반적인 영어 이름의 길이를 n이라고 했을 때, 검색 시간은 O(n)이 되지만, 대부분의 이름은 그리 크지 않은 상수값(예, 20자 이내)이기 때문에 O(1)이나 마찬가지라고 볼 수 있습니다.
생각해보기
트라이가 해시 테이블에 비해 가지는 장점과 단점은 무엇일까요?
장점: O(1)의 빠른 속도
단점: 엄청나게 많은 메모리 사용
반응형
'CS > 자료구조' 카테고리의 다른 글
| 9) 스택, 큐, 딕셔너리 (0) | 2022.06.07 |
|---|---|
| 7) 해시 테이블 (0) | 2022.06.07 |
| 6) 연결 리스트: 트리 (0) | 2022.06.07 |
| 5) 연결 리스트: 시연 (0) | 2022.06.07 |
| 4) 연결 리스트: 코딩 (0) | 2022.06.07 |