우리는 이제 다른 종류의 활성화 함수를 알아볼 것이다.
우리가 알고 있는 활성화 함수는 시그모이드, 소프트맥스와 같은 함수를 이미 알고 있다.
활성화 함수가 뭔지 까먹으신 분들을 위해 다시 개념을 정의 해보면
활성화 함수는 다음으로 전달될때 영향을 주는 함수라고 생각하면된다.
예를 들어 시그모이드의 경우 0~1 사이의 값을 전달해주는 함수처럼 이런 것을 활성화 함수라고 한다.
우리가 새로운 활성화 함수를 다시 배우는 이유가 있다.
딥러닝에서 다시 무엇인가를 찾는 이유는 대부분 성능이 안나와서이다.
우리는 딥러닝의 신경망이 깊고~ 넓어질수록 성능이 향상 됨을 알게되었다.
당연히 사람들은 신경망을 더우더욱 깊고 넓어지게 만들었지만 어느 시점이 되면 성능이 저하 되는 것을 알게 되었다.
Backpropagation을 하게 되면서 기울기 미분 값을 전달하게 되는데 그 값이 점점 희미해지는 현상이 발생하게 되었다.
우리는 이러한 것을 gradient vanish라고 부르게 되었다. 말 그대로 기울기가 소실 사라진다는 것이다.


예를 들어 설명을 해본다면 우리는 중간 중간에 있는 시그모이드라는 활성화 함수를 거치게 되면서 무조건 그 출력값은 0~1 사이의 값을 가지게 된다. 0~1 사이의 값이 출력 되는데 이게 처음에는 0.01이었다면 점점 0.0001이렇게 값이 0에 가까워 지게 되며 곱해진다. chain rule 때문이다.


따라서 힌튼 교수님은 우리 활성화 함수가 비선형이라 그런거 같아 다른걸로 적용하면 될거 같다는 의심을 하게 되었고
나온 함수가 relu 함수이다. x축의 값이 0이하라면 0의 값을 출력 해주고 나머지는 x 값을 따라서 출력 해주는 그래프이다.

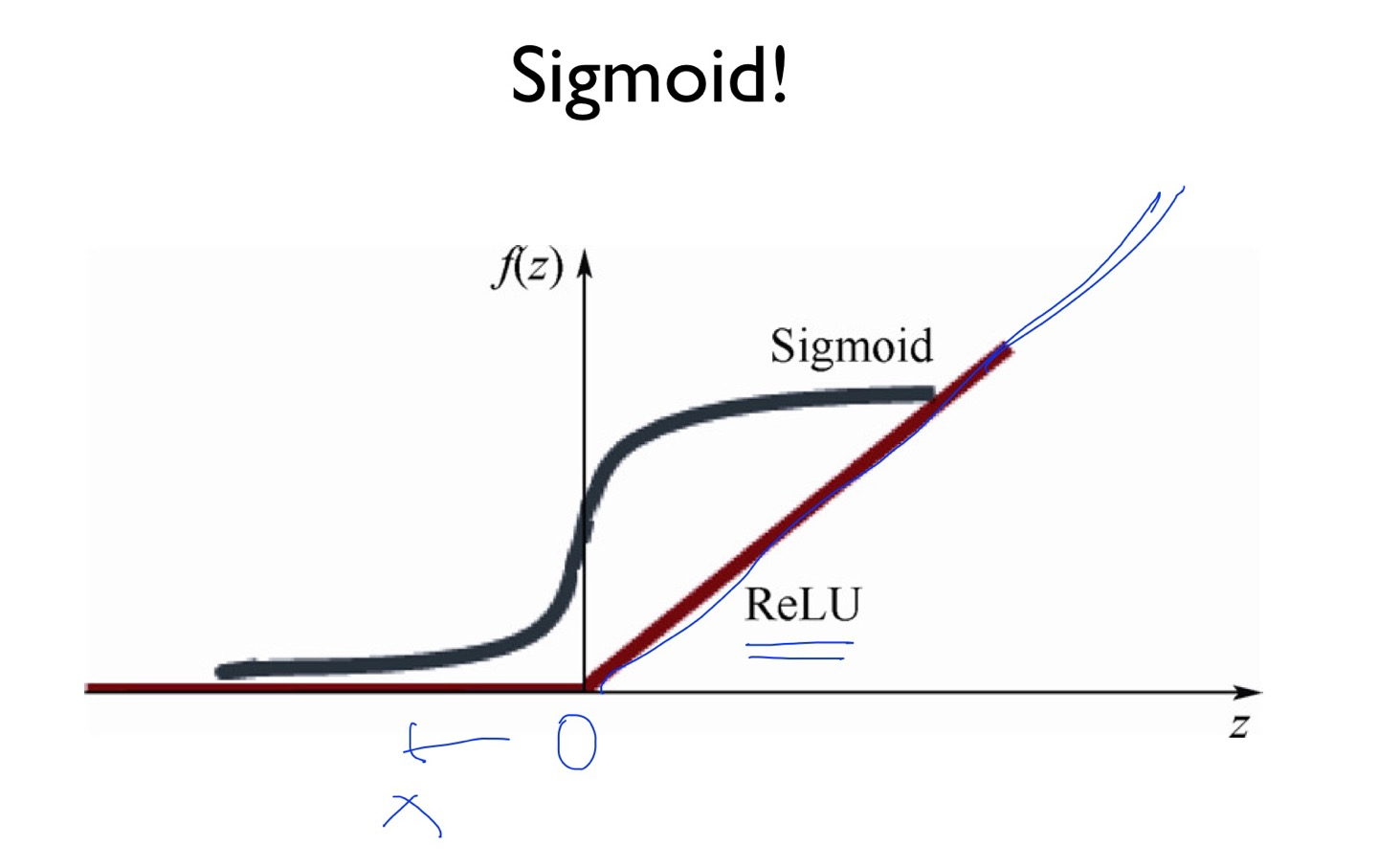
이러한 relu는 1보다 출력값을 출력하는 문제를 해결할 수 있었다.
최근에는 다양한 활성화 함수가 나오게 되었고 시그모이드는 마지막 층을 제외하고 중간에 있는 활성화 함수로는 안사용한다고 한다.


그리고 가장 최근에는 swish

라는 함수가 나오게 되면서 0이하의 값에서도 의미 있는 값을 출력 할 수 있게 해준다고 한다.
relu 땡큐!
'AI > 머신러닝(딥러닝) 정리' 카테고리의 다른 글
| 10-3. NN dropout and model ensemble (0) | 2022.05.05 |
|---|---|
| 10-2. Initialize weights in a smart way (0) | 2022.05.05 |
| 9-2. Backpropagation (0) | 2022.05.04 |
| 9-1. Neural Nets(NN) for XOR (0) | 2022.05.04 |
| 8-2. Deep Neural Nets (0) | 2022.05.04 |