우리는 vanishing을 해결했다.

다음 문제로는 우리는 가중치 값을 멍청하게 정했다는 것이다.
그럼 이번 장에서는 어떻게 초기 가중치 값을 어떻게 잘 줄까?
라는 것에 집중해보자


우리는 같음 함수로 학습을 시켰음에도 불구하고 모델의 성능이 다를 수 있는 것을 볼수 있다.
이러한 원인은 가중치 설정으로 인해 발생하는 것이다.

w를 우리는 일반적으로 -1~1 사이의 값을 준다. 램덤 값을 주는데
만약에 w의 초기 값을 0으로 주게된다면 chain rule 에서는 w 값을 사용해야하는데 다음 전달 값이 0이 된다.?!
그럼 전달을 해주는게 의미가 없게 되며 그 전달은 의미가 없는 학습이 되게 되는 것이다.
따라서 gradiant가 또 사라지게 된다.

따라서 모든 값을 0을 주게 된다면 안된다.
이러한 문제를 해결하기 위해 나온 것은 RBM이라는 것이 나왔다. 사실 너무 예전에 나온 것이라 최근에는 잘 사용을 하지 않는다고 한다. 그래도 알고 있는 것이 좋다. 다다익선! RBM을 사용해서 초기값을 잘 설정한다. 이러한 RBM을 사용해서 만든 NET이 DEEP Belief Nets 이다.

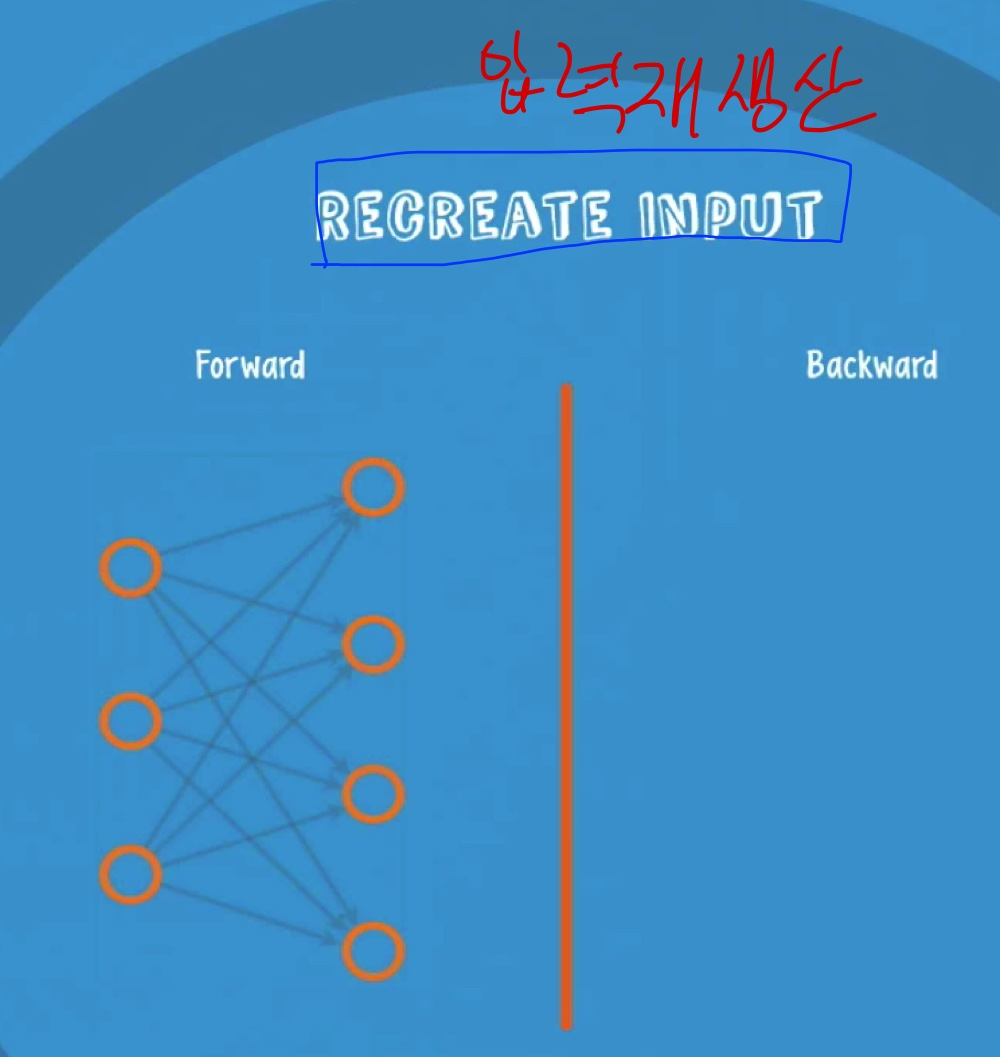
예를 들기 위해 우리는 입력단과 출력 단이 있다고 해보자.
어떤 입력 값이 있을 때 우리는 이 신경망에 두가지 과정이 있는데 이 과정의 목적은 입력을 재생산 하는 것이다.
이것이 무슨 말이냐면


어떠한 입력값 x1, x2, x3 가 있을 때 우리는 w1, w2,.....의 값을 곱하게 되면서 어떤 값을 출력하게 된다. 보낸 값을 우리는 다시 같은 w1, w2를 이용해 뒤로 보내준다.

이렇게 해서 나온 값을 우리는 두 x의 값의 차이가 최저가 되게 하는 w 값을 조정하는 것을 RBM 이라 한다.
다른 말로 encode, decode 라고도 한다.


위의 과정을 반복하며 학습을 진행하는 것이다.


우리는 이 과정을 진행할 때 label 값도 필요 없다. 이유는 x 값만 알고 비교하면 되니까
이렇게 우리는 앞으로 진행을 하며 pretrain과정을 진행한다. 그렇게 적절한 w 값을 찾으면 된다.
1,2 layer 에서 진행해주고 2,3 layer에서 진행해주고 다음 과정 진행해주고 이렇게 해주면된다.


우리는 이렇게 만들어진 가중치로 학습을 하게 되면 학습도 잘될뿐 아니라 학습도 다른 방식보다 훨씬 빠르게 된다고 한다. 그래서 우리는 이러한 것을 fine tuning이라고 부르게 되었으며 좋은 튜닝이라고 한다. 이미 w 가 잘되어있기 때문이다.
더 좋은 소식이 차후에 나온다. RBM 당연히 좋은 방법이지만 구현이 만만치 않다라는 점이다.

좋은 소식이란 우리는 복잡한 RBM을 사용 안해도 된다라는 점이다.
굉장히 간단한 초기값을 줘도 된다는 것이다.
우리는 Xavier initialization, he's initialization을 발견하였다.
하나의 노드에 몇개의 입력이고 몇개의 출력인가가 중요하다는 것이다. 그거에 비례하게 초기 값을 선택하면 된다는 것이다.

식이 입력이 몇개인가 출력이 몇개인가 중 입력의 수와 출력의 수사이의 값을 입력의 sqrt로 나눈 값을 뽑으면 RBM 과 비슷한 효과가 나온다는 것이다(무슨 근거로 저걸 발견한건지는 모르겠다.?!)
he라는 분이 발견한 것은 초기 값을 또 나누기 2를 해서 한게 더 좋은 성능을 냈다고 한다.
어떻게 발견한는 모르겠다.
아직도 초기값을 설정하는게 중요한 연구 분야라고 한다.( 현재도 고민중인지는 모르겠다.)

오늘의 요약
초기값 잘 설정하자.
'AI > 머신러닝(딥러닝) 정리' 카테고리의 다른 글
| 11-1. CNN (Convolutional Neural Networks) (0) | 2022.05.06 |
|---|---|
| 10-3. NN dropout and model ensemble (0) | 2022.05.05 |
| 10-1. ReLU : Better non-linearity (0) | 2022.05.05 |
| 9-2. Backpropagation (0) | 2022.05.04 |
| 9-1. Neural Nets(NN) for XOR (0) | 2022.05.04 |