python은 c, c++에 비하면 정말 느린 언어이다.
이러한 점을 극복하기 위한 것이 numpy이다. numpy는 파이썬 과학처리 패키지이다.


설치 방법 위의 activate는 가상환경이다.

ndarray
numpy 시작

사용법은 간단하다. 리스트 데이터를넣고 데이터 타입을 알려주면 된다.
파이썬의 특징 다이나믹 타이핑 미리 데이터를 선언하는 것이 아니라 써줄때마다 선언이 가능하다.
하지만 numpy는 허락하지 않는다. 데이터 타입을 선언해야한다.
따라서 하나의 데이터 타입만 들어간다.


파이썬에서의 특징은 일반적으로 메모리의 주소를 저장하는 방식이다.
따라서 a 라는 리스트가 존재할때 그냥 b를 복사해주면 b또한 a 와 같은 방향을 가리키게 되며 a를 변화 시켰을 때 b도 함께 변하는 것이다. 따라서 python 에서는 copy 라는 라이브러리를 사용한다.
이러한 이유때문에 파이썬은 느리다.

이런 점을 극복하기위해 나온 것이 numpy이의 ndarray이다. 데이터를 받아오는 방법이 다르다.

Array creation
test_array = np.array([1, 4, 5, "8"], float) # String Type의 데이터를 입력해도
print(test_array)
print(type(test_array[3])) # Float Type으로 자동 형변환을 실시
print(test_array.dtype) # Array(배열) 전체의 데이터 Type을 반환함
print(test_array.shape) # Array(배열) 의 shape을 반환함- shape : numpy array의 object의 dimension 구성을 반환함
- dtype : numpy array의 데이터 type을 반환함
딥러닝에서는 tensor 의 shape 이 중요하다. 따라서 꼭! 이해하자.

일반적인 벡터 타입의 텐서의 shape 이다.

다음은 우리가 알고 있는 행렬 타입의 텐서이며 모양은 3행 4열로 나타난다.

다음은 이미지 처리에 많이 사용되는 3차원 텐서이다. 바깥 쪽부터 세어주면 쉽다!
텐서의 차원이 하나하나 늘을때마다 하나씩 밀린다고 생각하면 쉽다.


- ndim – number of dimension 위의 예시에서는 뻗어나가는 방향이 3방향 이므로 3차원이다.
- size – data의 개수 위의 예시에서는 12 * 4 = 48 의 수이며
다음은 dtype 이다.


다음은 메모리의 크기인데 메모리의 크기는 어느정도 신경써주면서 학습을 해주어야한다.
이유는 너무 큰 메모리를 올리게 된다면 오류?가 나기 때문이다.

Handling shape
다음은 shape 핸들링이다. 우리는 아마 shape를 다루는 일을 많이 하게 될것이다.
첫번째로 reshape
- Array의 shape의 크기를 변경함 (element의 갯수는 동일)
reshape 의 경우에는 데이터의 사이즈만 고려하면 된다 그러면 변환이 된다.
아래의 예시는 8개만 맞추면된다.


우리가 reshape 를 해주게 될때 크기를 잘 모를때 -1 로 해주게 되면 알아서 데이터에 맞게 shape을 변환해주게 된다.

다음은 flatten 이다. 이 함수는 reshape 도 가능하지만 이걸 사용하면 더 쉽게 쫙 펴준다.


Indexing & slicing
우리는 일반적으로 python 에서 리스트의 인덱싱은 아래의 a[0][0] 으로 많이 하지만 numpy에서 a[0,0] 과 같은 방법으로도 사용한다.



다음은 slicing이다.

a = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]], int)
a[:,2:] # 전체 Row의 2열 이상
a[1,1:3] # 1 Row의 1열 ~ 2열
a[1:3] # 1 Row ~ 2Row의 전체- List와 달리 행과 열 부분을 나눠서 slicing이 가능함
- Matrix의 부분 집합을 추출할 때 유용함
아래의 예시를 보면 대괄호를 기준으로 앞은 행을 나타내며 뒤는 열을 나타내므로
앞의 행에서는 0,1 행 뒤에 열은 전체를 가져오게 된다.

아래의 예시를 보고 다시 확인할 수 있다.

이런건도 사용하는데 x: y : z 를 사용해서 x 시작지점, y는 끝 z 는 스텝을 나타낸다.

creation function
다음은 numpy arrary 를 생성하는 방법이다.
처음에는 arrange인데 우리가 아는 array 와 함께 사용하면된다.

그리고 일반적인 range에선 float의 값이 스텝이 안되지만 numpy 에서는 가능하다.
다음은 zeros 인데 이 함수는 자주 사용하는 함수이니 잘 알아두자~


empty 는 메모리 공간만 잡고 비워두는 건데 잘? 안사용하는거 같다.

something_like는 가끔 사용하는 함수인데 일반적으로 array를 반환해줄때 사용한다.



이런 함수도 있다. 대각행렬의 값을 가져온다.

random sampling 방식도 있다.

operation functions
numpy에서도 굉장히 많은 함수를 사용한다.
사용되는 함수는 다음과 같다.

다음은 중요한 개념인 axis 이다. 축!
shape 에서 가장 바깥쪽의 축이 0번째부터 시작하면 된다.
그래서 축끼리의 합을 구해라 라는 것을 아래의 예시에서 볼 수 있다.



다음은 mean & std 인데 있다고 정도만 이해하면 된다.
- ndarray의 element들 간의 평균 또는 표준 편차를 반환

그외의 함수...


다음은
concatenate 이다. 이함수는 엑셀? 에도 있는 개념이란다!
- Numpy array를 합치는 함수

vstack, hstack 은 두개의 축을 기준으로 붙이게된다.
다음은 concatenate라는 함수를 이용하는 것이다.
입력 값으로는 두 array와 축의 방향을 입력하면 합쳐주게 된다.
아마? 내가 알기로는 같은 축의 shape의 값이 같아야 하는 걸로 알고 있다.

array operations
다음은 중요한 array 연산이다. 우리가 아는 일반적인 행렬 연산을 그냥 해준다! ㄷㄷ
+- 는 상관 없지만 내적과 * 의 차이가 있다. * 는 그냥 같은 위치의 값과 곱해준다.

아래의 연산을 보면 일반적인 곱하기와 dot의 차이를 볼 수 있다.


다음은 transpose 전치도 가능하다.

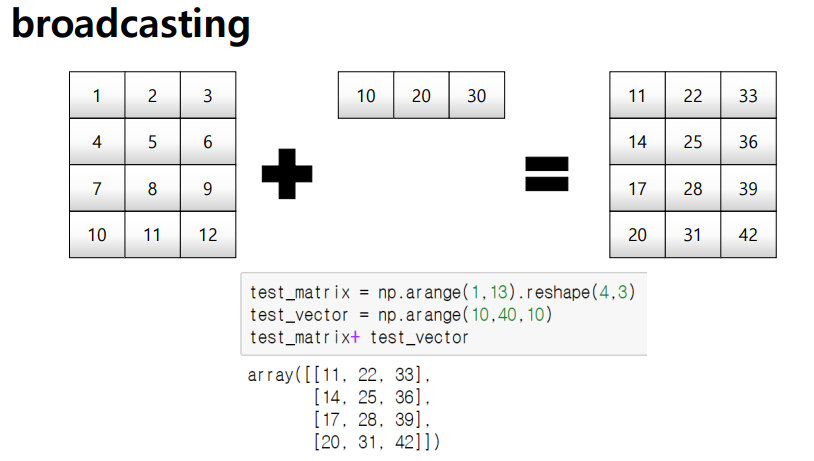
다음은 가장 중요한 개념인 broadcasting 이다.
broadcasting은 퍼트려 준다고 생각하면된다. 우리가 아는 broadcasting은 방송이니 퍼트려준다!
일반적으로 스칼라와 벡터에 사용이 된다.


아래의 예시를 볼수 있다. 행끼리 다 더하고 열끼리 다더하고

def sclar_vector_product(scalar, vector):
result = []
for value in vector:
result.append(scalar * value)
return result
iternation_max = 100000000
vector = list(range(iternation_max))
scalar = 2
%timeit sclar_vector_product(scalar, vector) # for loop을 이용한 성능
%timeit [scalar * value for value in range(iternation_max)] # list comprehension을 이용한 성능
%timeit np.arange(iternation_max) * scalar # numpy를 이용한 성능

comparisons
이거도 중요한 것이다.
비교인데 일종의 broadcasting 이 됐다고 생각하면 쉽다.
모든 값을 비교해 주면서 하게 된다.



np.where
np.where는 조건에 맞는 인덱스 값을 뱉어 낸다고 생각하면 쉽다!
이거랑 정렬하는 거랑 함께 많이 사용한다.

argmax & argmin
이건 진짜 많이 쓴다. 최대 값 최소값을 찾을때 쓴다.
인덱스를 알려준다 .최대 큰값 혹은 최소 값의 인덱스를 찾아준다.
그리고 축을 추가해주면 축에서의 최고 큰값 작은 값을 뽑아준다.

boolean & fancy index
boolean index 는 값을 뽑아낸다 where 과 차이가 있다.

이런식으로 조건에 만족하는 값을 뽑은후 이진분류를 할수도 있다. 아래와 같은 함수를 보면 이해가 쉽다.

fancy index는 인덱스에 값을 넣어주는 방법이다.
이건 추천 시스템에 많이 사용된다고 한다.

아래의 예시는 b의 인덱스는 행을 나타내며 c는 열의 인덱스를 나타낸다. 따라서 a 의 값을 이용해 행렬을 만들게 된다.

참고 사항 파이선의 피클이랑 같다

'AI > python AI' 카테고리의 다른 글
| python - pandas II (0) | 2022.06.03 |
|---|---|
| python pandas I (0) | 2022.06.03 |
| python - data handling (0) | 2022.06.01 |
| python - File / Exception / Log Handling (0) | 2022.06.01 |
| python - Module and Project (0) | 2022.06.01 |