panel data 의 줄임말인 pandas는 파이썬의 데이터 처리의 사실상의 표준인 라이브러리입니다.
pandas는 파이썬에서 일종의 엑셀과 같은 역할을 하여 데이터를 전처리하거나 통계 처리시 많이 활용하는 피봇 테이블 등의 기능을 사용할 때 쓸 수 있습니다. pandas 역시 numpy를 기반으로 하여 개발되어 있으며, R의 데이터 처리 기법을 참고하여 많은 함수가 구성되어 있거 기존 R 사용자들도 쉽게 해당 모듈을 사용할 수 있도록 지원하고 있습니다.
- Series
- DataFrame
- Selection & Drop
- Dataframe operation
- Lambda
- map
- apply
- Built-in functions



이제 데이터를 로딩 해오는 방식인데 sep 는 데이터를 나누는 기준인데 정규식을 넣는다. (위의 예시는 빈칸으로 구분한다는 것이다.)
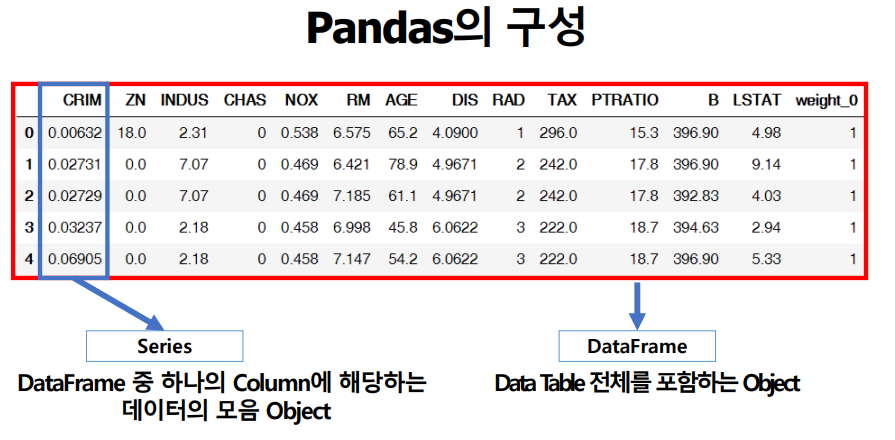
Series
pandas는 series 와 DataFrame 으로 구성 되어있다.

series 를 만들 수 있다.




series 는 이런 식으로 활용된다.


우리가 아는 리스트의 접근과 비슷하다! 차별점으로는 인덱스의 이름을 직접 넣어줘야한다.


series의 방법으로는 위와 같은 방법도 있다.
Dataframe

Dataframe 의 경우 row와 col 값만 안다면 접근이 가능하다는 특징이 있다.

또한 데이터 테이블도 만들수 있다.


이제부터 조금 중요한 내용이 나온다.
데이터에서 특정 내용만 필요한 경우가 있을 것이다. 우리는 이때 colums 라는 것을 활용하여 데이터를 가져오게 된다.

새로운 col을 추가해주게 된다면 NaN 이 자연스럽게 추가되어진다.

데이터를 가져오는 방식 또한 두가지 방식이 있는데 col의 이름을 가져오거나
.~~~이름 이런 식으로 가져오는 방식도 있다.
다음은 데이터에 접근하는 방법으로 index에 loctaion을 이용하는 방법이다.

위의 예시를 보면 df.loc[1]을 하게되면 1번 row 에 있는 줄을 가져오게 된다.
loc는 인덱스의 이름을 가지고 불러오는 방법이다.
다음 예시로는 iloc[1:]를 사용하게 되면 age 시리즈에서 1번부터 값을 불러오면 된다.
iloc는 인덱스의 위치를 가져오게 된다.


위와 같이 조건을 보면 loc는 이름을 가지고 활요하는것을 볼수 있다.
iloc는 숫자를 보고 결정한다.
다음은 데이터 프레임의 변환이다.
del 함수를 사용해서 삭제도 가능하다.


Selection & Drop
다음은 지우고 선택하는 것에 사용되는 것을 볼수 있다.
우리가 아는 numpy와 아주 비슷한 내용이다.

하나의 col을 가져올 때는 그냥 하나만 쓰면 되지만 1개 이상의 column을 선택할 때는 꼭 대괄호[ ] 를 포함시켜서 작성해줘야한다.
다음은 pandas에서 별로 안좋다고? 생각하는 것이란다.
그 이유는 대괄호 안에 이름을 넣어줬을 때는 column을 기준으로 가져오게 되지만
숫자를 넣어주게 되면 row를 기준으로 데이터를 가져온다는 점에서 일관성이 없다고 생각하기 때문이시란다!

다른 기능으로는 아래와 같은 기능이 있는데 약간 헷갈리는 문법이다!

다음으로 많이 사용하는 것은 index 변경이다.
기본 인덱스는 숫자로 되어있지만 인덱스를 사용하여 리셋이 가능하다.
아래의 예제에서 del account를 하는 이유는 지금까지 사용한 예제에서 col 에 account라는 열이 존재하기 때문에 지운거다! 큰 이유? 라고 해야하나 암튼 그렇다.


그리고 index를 재설정할 때 귀찮으면 list(range(0,~))이런 식으로 하면 알아서 정리를 해준단다.

다음은 데이터를 없애줄때이다.
방금 del을 이용해서 하는 방법도 있지만
행을 지울때는 drop를 사용한다고 한다.

drop를 사용하는 경우는 너무 많은 결측치를 포함할 때 많이 사용한다고 한다.

하지만 drop에 이름을 넣어주면 col을 지워주기도 하지만 axis 를 추가 해야한다는 점이 약간? 번거롭다.

그리고 약간 pandas의 특징이라고 할 수 있는데 위와 같은 방법으로 drop를 해준다고 해도 원본 데이터에는 변화가 없다 그 이유는 데이터를 다루는 것에 원본의 손상은 약간 위험하다고 생각하기 때문이다.
따라서 inplace 것을 넣어주면 결정이 가능하다고 한다.
Dataframe Operations
더하기 연산 같은 경우에는 인덱스의 이름이 같을 때 더해준다고 한다.

그리고 우리가 nan 값이 보기 싫을 때가 있는데 그때는 fill value 에 0을 넣게 되면 0으로 채우게 되며
문제를 해결 할 수 있다.


그리고 위와 같은 방법도 가능하다.

lambda, map, apply
다음은 lambda, map, apply 인데 이 함수들은 pandas에서 많이 사용되며 편하게 해준다고 한다?



이러한 식으로도 가능하다. map는 데이터에 변환을 줄때 역시 좋다!

이러한 식의 변환도 가능하다.


replace 함수도 있으니 각자 알아서...
apply이다.

apply는 col단위로 적용이되기 때문에 통계치를 적용하는데 많이 편하다고 한다.


applymap는 전체 데이터의 변환에 편하다고 한다.
Pandas Built-in functions
describe는 개괄적인 통계치를 보여준다고 한다.

unique 함수는 유일한 값을 반환해준다고 한다.

'AI > python AI' 카테고리의 다른 글
| python - pandas II (0) | 2022.06.03 |
|---|---|
| python - Numerical Python - Numpy (0) | 2022.06.02 |
| python - data handling (0) | 2022.06.01 |
| python - File / Exception / Log Handling (0) | 2022.06.01 |
| python - Module and Project (0) | 2022.06.01 |